
Sterling Crispin hat die Fratze der Überwachung studiert und mit seinem 3-D-Drucker ausgedruckt. Es ist eine Maske mit zerbeulter Oberfläche. Sie sieht aus wie Eiweiß, das in der Pfanne brutzelt und Blasen wirft. Doch ein Algorithmus sieht das anders. Wenn es nach ihm geht, ist die Antwort klar: Die Maske ist ein Menschengesicht, zusammengesetzt aus den verfügbaren Informationen. Ein Jahr hat Crispin gebraucht, bis er die Maske in den Händen halten konnte. Jetzt sagt er: "Das ist, wie Maschinen uns sehen. Das ist sehr verstörend."
Verstörend ist das für Crispin nicht nur, weil die Maske so unmenschlich aussieht, womit er - im Gegensatz zur Maschine - nie gerechnet hätte. Ihn irritiert vor allem die Botschaft dahinter: Diese fremde Fratze ist Grundlage für mächtige Überwachungssysteme. Wenn Polizisten im kalifornischen San Diego Tablets mit auf Streife nehmen und damit verdächtige Personen fotografieren, gleicht die Software dieses Bild mit einer Datenbank ab; dieser Abgleich basiert auf Algorithmen. Der Maschinenblick rückt in den Mittelpunkt der Polizeiarbeit.
Das FBI geht so ähnlich vor. Mit seinem Programm "Next Generation Identification System", also der nächsten Generation der Identifizierung, will die Behörde bis 2015 mehr als 52 Millionen Gesichter in ihre Datenbank aufnehmen. "Sie vermischen Bilder von Menschen, die vorbestraft sind mit Fotos von Unschuldigen", sagt Crispin. Das FBI gibt an, dass es mit einer Wahrscheinlichkeit von 85 Prozent den Täter finde - wenn dessen Bild überhaupt in der Datenbank ist, tauche es in den ersten 50 Vorschlägen auf. "Diese Quote ist sehr niedrig", sagt Crispin, sichtlich empört, "faktisch heißt das, dass 49 unschuldige Menschen als potenzielle Täter vorgeschlagen werden für ein Verbrechen, mit dem sie nichts zu tun haben."
Je unterschiedlicher die Bilder, desto besser lernt der Algorithmus
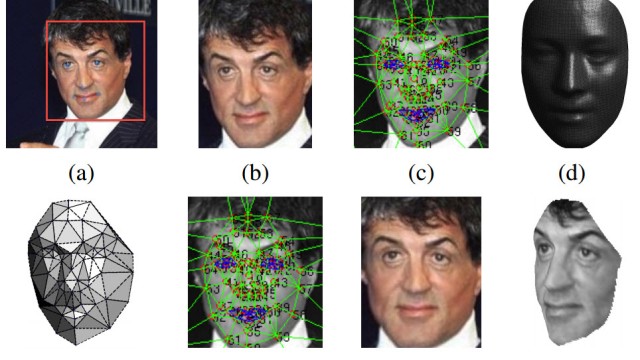
Crispin ist 29 Jahre alt und studiert Multimediatechnik an der University of California in Santa Barbara. Das Projekt "Data Masks" ist seine Abschlussarbeit, an diesem Freitag wird er sie einreichen. Crispin hat ein Jahr lang analysiert, wie genau ein Algorithmus bei Gesichtserkennung vorgeht. Algorithmen muss man sich vorstellen wie Rezepte. Sie durchlaufen klar definierte Einzelschritte und liefern so Ergebnisse. Die Variante des Algorithmus, die Crispin eingesetzt hat, ist lernfähig. Je mehr Daten sie bekommt, desto besser kann sie ihre Ergebnisse verfeinern.
Also hat Crispin eine Bilder-Datenbank mit 6000 Gesichtern gewählt, die frei im Netz verfügbar ist - in ihr sind eine Vielzahl von Hautfarben, Geschlechtern und Blickrichtungen enthalten. Je unterschiedlicher die Bilder sind, desto eher lernt der Algorithmus. Passfotos zum Beispiel, auf denen Menschen klassischerweise mit geradem Blick, meist ohne zu lächeln, in die Kamera gucken, vermitteln ein anderes Bild der Realität, als das Urlaubsfotos tun. Die Datenbank bietet also eine große Auswahl, um die Besonderheiten eines menschlichen Gesichts zu erkennen. Diese Gesichter dienen für das Programm als Grundlage. Es analysiert, wie ein Gesicht normalerweise ausschaut. Werden ihm Bilder vorgelegt, prüft der Algorithmus auf dieser Basis, ob auf dem ihm vorgelegten Bild ein Gesicht zu sehen ist.
Das Bild stammt aus einem Forschungsbericht, den Facebook veröffentlicht hat.
Verglichen mit Facebook, dem sprichwörtlichen Gesichtsbuch, sind 6000 Bilder natürlich wenig. Auf Facebook werden jeden Tag 350 Millionen Fotos hochgeladen und das ist der Stand von 2013. Mittlerweile dürften es deutlich mehr sein. Auf Instagram, das ebenfalls zu Facebook gehört, landen täglich 70 Millionen Fotos (wobei diese Zahl auch die hochgeladenen Videos enthält).
Ein Gesicht, aufgeteilt in zahllose Rechtecke und Pixel
Die Art der Gesichtserkennung, die auch Facebook einsetzt, dürfte jedoch der Variante von Crispin ähneln. Er hat in Eigenregie eine Software entwickelt. Er hat Codeschnipsel aus wissenschaftlichen Arbeiten übernommen und viel davon auch selbst geschrieben. Das 2-D-Modell eines Gesichts wird zum Beispiel in unzählige Rechtecke zerteilt und der Algorithmus prüft, wie sehr sich das Endergebnis mit den Resultaten deckt, die, laut Algorithmus, für menschliche Mimik stehen. Dabei geht es um Details, die so groß sind wie ein Pixel und nicht darum, zu erkennen, wie genau eine Nase oder ein Mund aussieht.
Da die Rechnung von einem Algorithmus vorgenommen wird, kann sie so automatisiert werden, das es ein Vorgang ist, der stundenlang abgleicht, mit unzähligen Versuchen - und entsprechend besseren Ergebnissen. "Stell dir vor, du züchtest 1000 Hunde für zehntausend Jahre, aber nur diejenigen mit langen Ohren dürfen ihre Gene weitergeben", sagt Crispin, um seine Arbeit anschaulicher zu erklären. "Am Ende haben alle Hunde lange Ohren."
"Ich bin mir nicht sicher, ob es gut ist, diese autonomen Systeme zu trainieren", sagt Crispin. Er findet, dass Menschen sich nicht auf diese Systeme verlassen sollten. Wenn das die Art sei, wie Menschen von Maschinen analysiert werden - als statistische Muster -, sei es gefährlich, das als Beweis zu behandeln. Daten seien fälschbar.
Seine Datenmaske ist ein Akt des politischen Protests durch Transparenz. Nach dem Motto: Man muss wissen, worüber man genau redet. Seine Masken sind eine Versinnbildlichung dessen, was sonst als unsichtbare Technik beschrieben wird. Gesichtserkennungs-Algorithmen existieren, arbeiten, sind aber in der Regel nicht sichtbar. Menschen haben keinen Begriff davon, was es heißt, überwacht zu werden. Crispin hat daran gearbeitet, das zu ändern.